
Lors de la CitizenCon 2951, nous avons plongé dans les technologies de transformation que sont le Server Meshing et le Persistent Streaming, avec Paul Reindell (directeur de l’ingénierie, Online Technology) et Benoit Beausejour (directeur de la technologie chez Turbulent). Après le panel, nous avons constaté que de nombreuses personnes avaient des questions à poser à nos panélistes, et nous voulons nous assurer qu’elles reçoivent une réponse. Nous vous invitons à lire la suite de notre entretien avec Paul, Benoit, Roger Godfrey (producteur principal) et Clive Johnson (programmeur réseau principal).
Quand verrons-nous le Streaming persistant et le Server Meshing dans le PU ?
Notre objectif actuel est de publier le streaming persistant et la première version de la couche de réplication, idéalement entre le premier et le deuxième trimestre de l’année prochaine. Nous poursuivrons ensuite avec la première version d’un maillage de serveurs statiques, sauf complications techniques imprévues, entre le troisième et le quatrième trimestre de l’année prochaine.
Quel est l’état actuel de la technologie de maillage des serveurs et quels sont les principaux problèmes qui la freinent ?
La plupart des gens, lorsqu’ils parlent de maillage de serveurs, pensent généralement à l’étape finale de cette technologie où nous « maillons les serveurs ensemble ». La vérité est qu’avant cette étape finale, une très longue chaîne de pré-requis et de changements technologiques fondamentaux doivent être apportés à notre moteur de jeu. En gardant cela à l’esprit, je vais essayer de répondre à cette question en tenant compte de l’ensemble du tableau.
La réponse courte est que l’état est en fait très avancé.
Maintenant, la version longue. La route vers le maillage de serveurs a commencé en 2017/2018 :
Streaming de conteneurs d’objets
Pour que le Server Meshing fonctionne, nous avions d’abord besoin d’une technologie qui nous permette de lier/délier dynamiquement des entités via le système de streaming, car ce n’est pas quelque chose que le moteur prenait en charge lorsque nous avons commencé. Ainsi, lorsque nous avons lancé le « Client Side Object Container Streaming » (OCS) en 2018, nous avons également lancé la toute première étape vers le maillage de serveur !
Une fois ce premier pas franchi, la technologie qui nous permet de lier/délier dynamiquement des entités sur le client devait être activée sur le serveur également (car, en fin de compte, les nœuds de serveur dans le maillage devront diffuser des entités en entrée/sortie de manière dynamique). Cette technologie est appelée « Server Side Object Container Streaming » (S-OCS), et la première version de S-OCS a été publiée à la fin de 2019. Il s’agissait de la prochaine grande étape vers le maillage de serveur.
Autorité des entités et transfert d’autorité
Alors que nous disposions de la technologie nous permettant de diffuser dynamiquement des entités sur le serveur, il n’y a toujours qu’un seul serveur qui « possède » toutes les entités simulées. Dans un maillage où plusieurs nœuds de serveur partagent la simulation, nous avons besoin du concept d' »autorité des entités ». Cela signifie qu’une entité donnée n’est plus la propriété d’un seul serveur de jeu dédié, mais qu’il existe plusieurs nœuds de serveur dans le maillage. Ainsi, un nœud de serveur qui contrôle l’entité, et plusieurs autres nœuds de serveur qui ont une vue client de cette entité. Cette autorité doit également pouvoir être transférée entre les nœuds de serveur. Une bonne partie du temps de développement a été consacrée au concept d' »autorité de l’entité » et de « transfert d’autorité » au cours du premier semestre de 2020. C’est la première fois que l’ensemble de l’entreprise a dû travailler sur le maillage des serveurs, car une grande partie du code de jeu a dû être modifiée pour fonctionner avec le nouveau concept d’entité-autorité. À la fin de l’année 2020, la plupart du code (de jeu) a été modifié pour prendre en charge le concept, donc une autre grande étape a été franchie, mais il n’y a pas encore de maillage réel en vue.
Couche de réplication et flux persistant
L’étape suivante a consisté à déplacer la réplication des entités dans un endroit central où nous pouvons contrôler le streaming et la logique de liaison au réseau. Cela nous permet ensuite de répliquer l’état du réseau sur plusieurs nœuds de serveur. Pour ce faire, nous avons dû déplacer la logique de streaming et de réplication du serveur dédié vers la couche « Réplication », qui héberge désormais le code de réplication du réseau et de streaming des entités.
Dans le même temps, nous avons également implémenté le streaming persistant, qui permet à la couche de réplication de faire persister l’état des entités dans une base de données de graphes qui stocke l’état de chaque entité répliquée en réseau. L’année 2021 a été consacrée au travail sur la couche de réplication et l’EntityGraph, qui nous permet de contrôler le streaming et la réplication des entités à partir d’un processus distinct (séparé du serveur de jeu traditionnel dédié). Ce travail est presque terminé et se trouve dans sa phase finale.
Maillages de serveurs statiques et dynamiques
Cependant, ce n’est pas encore un « maillage ». Le travail sur le maillage proprement dit a commencé et il nous faudra une bonne partie de l’année prochaine pour le terminer, et toutes les conditions préalables que j’ai décrites ci-dessus étaient nécessaires pour en arriver à ce point. La première version de cette technologie sera un maillage de serveurs statiques et constitue le prochain grand pas en avant. Cependant, ce ne sera pas non plus la dernière ! Avec le maillage statique, nous disposerons de la première version d’un véritable maillage mais, comme le nom « statique » l’indique, la capacité à faire évoluer ce maillage est très limitée.
Avant de pouvoir vraiment qualifier cette fonctionnalité de complète, nous devrons franchir une autre étape importante, que nous appelons « maillage dynamique ». Cette étape nous permettra de mailler dynamiquement les nœuds de serveur ensemble, puis de faire évoluer le maillage dynamiquement en fonction de la demande. Une grande partie du travail sur cette partie se fait en parallèle. Par exemple, le gestionnaire de flotte qui contrôle la demande dynamique du maillage est déjà en cours de développement, de même que les exigences en matière de matchmaking qui accompagnent la nouvelle inclusion des « shards ».
Pendant ce temps, de nombreuses équipes de code de jeu doivent également travailler à l’adaptation du code de jeu existant pour qu’il fonctionne pleinement avec un maillage de serveur (et surtout trouver tous les cas limites qui ne feront surface qu’une fois que nous aurons un véritable maillage). Bien que le travail sur l’autorité des entités ait été achevé en 2020, l’autorité des entités n’est actuellement transférée qu’entre le client et un seul serveur, de sorte que certains codes peuvent nécessiter des ajustements supplémentaires.
Comment envisagez-vous de gérer un grand vaisseau, par exemple un Javelin ? Serait-il une ressource dédiée à part entière avec des vaisseaux autour de lui ?
Avec le maillage dynamique du serveur, il est possible que les grands vaisseaux, comme le Javelin, aient leur propre serveur dédié pour exécuter la simulation faisant autorité pour ce vaisseau et tout ce qu’il contient. Cependant, nous essayons d’éviter d’avoir des règles inflexibles sur la façon dont les entités sont assignées aux ressources de traitement, donc ce ne sera pas toujours le cas. C’est une question d’efficacité, tant en termes de vitesse de traitement que de coûts de serveur. Si nous avions une règle stricte selon laquelle chaque Javelin et tout ce qu’il contient reçoit son propre serveur, cela ne serait pas très rentable lorsqu’un Javelin ne compte qu’une poignée de joueurs. La même règle ne serait pas non plus efficace en termes de vitesse de traitement des serveurs s’il y avait des centaines de joueurs entassés dans le même Javelin, car la règle nous empêcherait de répartir la charge de traitement sur plusieurs serveurs.
Le maillage dynamique des serveurs sera un peu différent dans la mesure où il réévaluera constamment la meilleure façon de distribuer la simulation, afin de trouver le point idéal pour qu’aucun serveur ne soit surchargé ou sous-utilisé. Au fur et à mesure que les joueurs se déplacent dans le verse, la distribution idéale des ressources de traitement changera. Pour réagir à ces changements, nous devrons être en mesure de transférer l’autorité sur les entités d’un serveur à un autre, ainsi que de mettre en ligne de nouveaux serveurs et de fermer les anciens. Cela nous permettra de déplacer la charge de traitement d’un serveur qui risque d’être surchargé vers un serveur qui est actuellement sous-utilisé. Si aucun des serveurs existants ne dispose d’une capacité de réserve suffisante pour faire face à une augmentation de la charge, nous pouvons simplement louer d’autres serveurs auprès de notre fournisseur de plateforme en nuage. Et lorsque la charge de certains serveurs n’est plus suffisante pour les rendre rentables, certains d’entre eux peuvent transférer leurs parties de la simulation sur les autres et nous pouvons fermer ceux dont nous n’avons plus besoin.
Combien de joueurs pourront se voir dans un même espace ? Quel est le maximum que vous prévoyez ?
Il est difficile de répondre à cette question, et la meilleure réponse que nous puissions donner pour le moment est que cela dépend.
En supposant que la question porte sur la limite du nombre de joueurs qui pourront se voir d’un point de vue client, elle est principalement dictée par le client du jeu. Cela est dû à la simulation côté client, comme la physique et le code de jeu, ainsi qu’au coût du rendu.
De plus, cela dépend aussi fortement du scénario ; 100 joueurs en combat FPS sont moins chers à simuler et à rendre sur le client que 100 joueurs se battant dans des vaisseaux spatiaux monoplaces, se tirant des missiles et des lasers.
L’équipe graphique travaille activement sur Vulkan, qui nous permettra d’augmenter les appels de dessin et devrait améliorer le nombre de joueurs/de vaisseaux que nous pouvons rendre en même temps, tandis que l’équipe moteur se concentre sur les optimisations du code de jeu pour augmenter le nombre d’objets de jeu que nous pouvons simuler en même temps.
Notre objectif est d’augmenter le nombre de joueurs et nous espérons pouvoir supporter des scénarios dans lesquels 100 joueurs peuvent se voir à des fréquences d’images raisonnables. Cependant, lorsque nous commencerons à mettre à l’échelle nos shards pour supporter un nombre plus élevé de joueurs, la probabilité que chaque joueur d’un shard puisse se rendre au même endroit physique et se voir sans problème de performance diminuera.
C’est là que nous devrons commencer à mettre en place des mécanismes de jeu qui empêcheront ces scénarios de se produire trop fréquemment.
La limite absolue est difficile à prévoir tant que les nouvelles technologies ne sont pas en ligne et que nous ne pouvons pas commencer à mesurer les performances.
Si je construis une base sur une lune, ma base sera-t-elle reflétée sur les autres shards sur lesquels je ne suis pas ?
L’équipe de Planet Tech prévoit d’implémenter la construction de bases en tenant compte des shards du serveur. En revendiquant un terrain pour votre base, vous revendiquerez ce terrain sur tous les serveurs, et nous prévoyons de répliquer votre base sur tous les serveurs.
Cependant, un seul serveur disposera d’une version « active » de la base, les autres serveurs générant une version « accès limité/lecture seule » de cette même base. Par exemple, une base donnera un accès complet et la possibilité de s’étendre dans le shard sur lequel le propriétaire joue actuellement, tandis que sur tous les autres shards, cette base peut apparaître avec des portes verrouillées dans un état immuable. La conception complète n’est pas encore établie à 100% et peut changer cependant.
Est-ce que le véritable objectif final est un seul shard pour tous les joueurs ?
C’est notre ambition, mais il n’est pas possible de donner une réponse définitive à ce stade.
Nous commencerons avec de nombreux petits shards par région et réduirons lentement le nombre de shards. Le premier objectif majeur sera de réduire le nombre de shards à un seul par région. Pour y arriver, notre plan est d’augmenter progressivement le nombre de joueurs par shard et d’améliorer constamment le backend et la technologie client pour supporter de plus en plus de joueurs.
Il n’y a pas que les changements technologiques qui sont nécessaires pour atteindre cet objectif – une nouvelle conception du jeu et des mécanismes de jeu sont également nécessaires. Sans mécanismes pour empêcher chaque joueur de se rendre au même endroit, un grand méga-shard sera très difficile à réaliser, surtout sur le client. Par exemple, il pourrait y avoir un mécanisme permettant de fermer temporairement les points de saut vers des endroits bondés, ou de créer de nouvelles couches pour certains endroits.
Alors que le backend est conçu pour évoluer horizontalement, le client de jeu fonctionne sur une seule machine et est limité à un nombre défini de cœurs CPU/GPU ainsi qu’à la mémoire.
Ce n’est qu’une fois que nous aurons surmonté ces obstacles et réussi à créer un méga-shard par région que nous pourrons nous attaquer au boss final : Fusionner les shards régionaux en un méga-shard global.
Cela pose son lot de problèmes, car la localisation joue un rôle important dans l’expérience du joueur. Par exemple, la latence entre les services au sein d’un même centre de données est beaucoup plus faible que la latence entre des services hébergés dans deux centres de données séparés par région. Et bien que nous ayons conçu le backend pour supporter un shard global, c’est un défi opérationnel de déployer le backend de manière à ne pas favoriser un groupe de joueurs par rapport à un autre.
L’économie de l’univers sera-t-elle indépendante dans chaque shard ou jointe ?
L’économie sera globale et reflétée dans chaque shard.
Par exemple, prenons le cas des boutiques. Alors que chaque boutique dispose d’un inventaire local (les articles qui sont actuellement exposés), les boutiques sont réapprovisionnées à partir d’un inventaire global partagé par tous les shards. Si de nombreux joueurs commencent à acheter une arme spécifique à la boutique d’armes de Port Olisar, le prix de cette arme augmentera dans cette boutique sur tous les mondes. Le stock de cette arme finira par être épuisé, et les magasins de tous les mondes ne pourront plus la réapprovisionner.
Qu’est-ce qui empêchera de grands groupes de « bleus » et de grands groupes de « rouges » de se retrouver dans des shards ? La dynamique sociale impliquerait de grandes concentrations de personnes qui auront des amis et seront dans des orgs qui ont les mêmes intérêts. Y aura-t-il une solution pour assurer un bon mélange entre les bons, les mauvais et les intermédiaires ?
Les joueurs ne seront pas assignés de façon permanente à des shards, car le système de matchmaking attribue un nouveau shard pour la région sélectionnée à chaque connexion. Au début, cela entraînera une distribution naturelle, car nous commencerons avec de nombreux petits shards en parallèle.
Lorsque nous commencerons à faire évoluer nos shards (et donc à réduire le nombre de shards parallèles), cette question deviendra plus pertinente. Nous prévoyons d’y répondre avec notre nouveau système de mise en relation.
Le nouveau système de mise en relation, actuellement en cours de développement parallèlement au maillage des serveurs, nous permet d’associer les joueurs aux shards en fonction de plusieurs paramètres d’entrée. Ces paramètres sont utilisés pour associer les joueurs à leurs amis ou à l’endroit où ils ont laissé la plupart de leurs objets dans le monde ouvert. Cependant, il nous permet également d’utiliser des paramètres plus avancés, tels que la réputation et d’autres statistiques cachées des joueurs que nous suivons.
Cela nous permettra d’essayer de faire en sorte que chaque shard présente une collection semi-diversifiée d’individus. Par exemple, nous pourrions nous assurer que nous ne chargeons pas par inadvertance un shard avec uniquement des joueurs légaux, ce qui pourrait ne pas être très amusant si une partie de ce qu’ils veulent faire est de chasser les joueurs criminels.
Votre personnage et votre vaisseau seront-ils toujours présents dans le jeu après votre départ ? Par exemple, si je me déconnecte du lit de mon vaisseau sur une planète, mon vaisseau sera-t-il toujours là, ce qui signifie que des personnes pourraient essayer de s’y introduire ou de le détruire ?
Lorsqu’une entité est « déstockée » dans un shard (elle existe physiquement dans le shard), elle existe de manière permanente dans ce shard jusqu’à ce que le joueur « range » l’entité dans un inventaire. Cela peut se faire en ramassant une arme et en la plaçant dans votre sac à dos, ou en faisant atterrir un vaisseau sur une aire d’atterrissage, ce qui place le vaisseau dans un inventaire spécifique de l’aire d’atterrissage. Une fois qu’une entité se trouve dans un inventaire, elle est stockée dans la base de données globale et peut être rangée dans n’importe quel shard. Cela permet aux joueurs de déplacer des objets entre les shards.
Nous prévoyons également un mécanisme appelé « arrimage/désarrimage des objets de héros ». Cela prendra tous les objets de héros appartenant au joueur et les rangera automatiquement dans un inventaire de transition de shard spécifique au joueur. Le rangement automatique se produit généralement lorsqu’aucun autre joueur n’est présent et que l’entité est diffusée. Les objets de cet inventaire de transition suivront automatiquement le joueur. Ainsi, lorsqu’un joueur se connectera à un autre shard, nous prendrons les entités et les rangerons dans le nouveau shard à l’endroit où le joueur les a laissées.
Lorsque vous posez votre vaisseau sur une lune et que vous vous déconnectez, le vaisseau disparait et est automatiquement rangé si aucun autre joueur n’est présent à ce moment-là. Maintenant, lorsque vous vous connectez à un autre shard, votre vaisseau sera déplacé dans ce nouveau shard. Si, pour une raison quelconque, le vaisseau est resté plus longtemps dans l’ancien shard et a été détruit alors que vous étiez déconnecté, vous pouvez vous réveiller dans un lit médicalisé.
Dans quelle mesure le nouveau contenu dépend-il maintenant du maillage de serveurs ?
Le maillage de serveurs nous permettra de commencer à augmenter le nombre de joueurs pouvant jouer ensemble dans Star Citizen, mais aussi de commencer à ajouter de nouvelles expériences de contenu. Pour l’instant, nous nous concentrons sur l’ajout de nouveaux systèmes stellaires. Le maillage de serveurs est l’une des technologies clés pour faire fonctionner les points de saut dans le jeu, en permettant aux systèmes stellaires d’entrer et de sortir de la mémoire de façon transparente, sans écran de chargement. Les joueurs le verront pour la première fois l’année prochaine, lorsque la première itération du Server Meshing sera mise en service avec l’introduction du système Pyro.
Au fur et à mesure que nous affinons la technologie et que nous nous éloignons du maillage statique des serveurs pour nous rapprocher du maillage dynamique des serveurs, les concepteurs peuvent utiliser cette technologie pour créer des zones plus grandes et plus intéressantes (comme des colonies ou des intérieurs de vaisseaux plus grands) avec un nombre plus dense de personnages IA et de joueurs. Le maillage de serveurs pourrait ouvrir les portes à des expériences de jeu auxquelles nos concepteurs n’ont pas encore pensé !
Quelle proportion du nouveau contenu dépend maintenant du maillage des serveurs ?
Le maillage des serveurs nous permettra de commencer à augmenter le nombre de joueurs qui peuvent jouer ensemble dans Star Citizen, mais aussi de commencer à ajouter de nouvelles expériences de contenu. Pour l’instant, nous nous concentrons sur l’ajout de nouveaux systèmes stellaires. Le maillage des serveurs est l’une des technologies clés pour faire fonctionner les points de saut dans le jeu, permettant aux systèmes stellaires d’entrer et de sortir de la mémoire de façon transparente sans écran de chargement. Les joueurs le verront pour la première fois l’année prochaine, lorsque la première itération du maillage des serveurs sera mise en service avec l’introduction du système Pyro.
Au fur et à mesure que nous affinons la technologie et que nous passons du maillage statique des serveurs au maillage dynamique des serveurs, les concepteurs peuvent utiliser cette technologie pour créer des zones plus grandes et plus intéressantes (comme des colonies ou des intérieurs de vaisseaux plus grands) avec un nombre plus dense de personnages IA et de joueurs. Le maillage de serveurs pourrait ouvrir les portes à des expériences de jeu auxquelles nos concepteurs n’ont pas encore pensé !
Quelle est l’ampleur de l’amélioration des performances à laquelle nous pouvons nous attendre ?
Le gain le plus important sera la performance du serveur. Actuellement, les performances de notre serveur sont assez limitées en raison du nombre d’entités que nous devons simuler sur un serveur. Il en résulte un framerate très bas et une dégradation du serveur, ce qui entraîne pour le client un lag/rubber banding et d’autres problèmes de désynchronisation du réseau. Une fois que nous aurons mis en place le maillage statique, le framerate du serveur devrait être considérablement plus élevé, ce qui réduira ces symptômes.
En ce qui concerne les FPS du client, le maillage du serveur a en fait très peu d’impact. Le client ne diffuse déjà que les entités qui sont à portée de vue. Il peut y avoir de légères améliorations, car nous pouvons être un peu plus agressifs avec l’élimination de la portée sur le client car, actuellement, certains objets ont un rayon de diffusion gonflé pour que des fonctionnalités comme le radar ou les missiles fonctionnent correctement. Avec le Server Meshing, nous pouvons découpler le rayon de diffusion du client et du serveur. Cependant, ces améliorations seront minimes sur le client. Néanmoins, des FPS plus rapides sur le serveur amélioreront l’expérience globale car le décalage du réseau sera considérablement réduit.
Je sais qu’il n’y a peut-être pas encore de réponse à cette question mais, lors de la sortie initiale du Server Meshing, combien de shards pensez-vous devoir avoir ? 10, 100, 1000, plus ? Nous savons que l’abandon de DGS signifie plus de joueurs par zone de jeu, mais nous ne savons pas combien vous en prévoyez.
La réponse courte est que nous ne pouvons pas avancer un nombre.
Le concept de shard est la partie « malléable » de l’architecture de maillage, et nous ne serons en mesure de dire le nombre de shards requis qu’une fois que tous les composants seront en place et que nous prévoyons d’y arriver par itération.
Avec la première goutte de Persistent Streaming (pas de maillage), nous voulons commencer par imiter le comportement actuel que vous voyez en ligne en ayant un shard par instance de serveur et un réplicant (appelé l’hybride). La seule différence est que toutes les entités de ces shards seront toujours persistantes. Cela nous permet de faire face au pire des scénarios en ayant un très grand nombre de shards persistants et de réplicants de très grande taille pour tester les mécanismes de création/ensemencement, de simulation avec des joueurs actifs et de démantèlement pour recyclage ou destruction. Nous voulons que la création et la destruction des shards dans cette première phase soient optimales, rapides et neutres en termes de coûts.
Cette approche a plusieurs avantages, car nous pouvons tester la persistance des shards plus tôt et, plus important encore, nous pouvons mesurer les métriques actives sur de nombreux shards.
Par exemple (non exhaustif !) :
- Combien d’entités restent dans un shard persistant au fil du temps (taux de croissance du shard).
- Taille du graphe global (taux de croissance global)
- Combien de joueurs une base de données d’un seul shard peut-elle gérer (utilisation des joueurs) ?
- L’effet de plusieurs mécanismes de jeu sur les mises à jour des entités dans la base de données du shard (effets du jeu).
- Profil de performance des files d’attente d’écriture, temps de requête moyen des clusters de la base de données shard (métriques de la base de données shard)
- Profil de performance des files d’attente d’écriture, temps moyen d’interrogation du cluster global de la base de données (métriques de la base de données globale)
- Efficacité du sharding de la base de données (un autre niveau de sharding !) du graphe
- Bien que nous disposions d’estimations et de mesures internes appropriées pour ces éléments, rien ne remplace des acteurs réels générant une charge représentative sur le système.
Au fur et à mesure que nous mettons en place les autres composants du maillage, principalement le maillage statique, nous prévoyons de réduire progressivement le nombre de shards, en regroupant les joueurs dans des shards de plus en plus grands jusqu’à ce que nous soyons à l’aise avec les performances des réplicants, des DGS et du graphe d’entités. Bien sûr, le maillage statique souffrira de problèmes de congestion et nous ne pourrons reprendre le passage à des shards beaucoup plus grands qu’une fois le maillage dynamique en place.
En fin de compte, avec le maillage dynamique, nous visons à supporter de très grands shards.
Est-ce qu’un bien aussi petit qu’une balle peut voyager d’un serveur à l’autre ?
La réponse courte est non.
Vous pouvez considérer les shards comme une instance complètement isolée de l’univers simulé, très similaire à la façon dont nous avons actuellement différentes instances isolées par serveur dédié. Pour que les objets puissent être transférés d’une instance à l’autre, ils doivent être rangés dans un inventaire avant de pouvoir être détachés dans un autre shard. Par exemple, si un joueur ramasse une arme dans un shard et la place dans son sac à dos. Lorsque le joueur se connecte à un autre espace, il peut sortir l’arme de son sac à dos et la ranger dans le nouvel espace.
Au sein d’un shard, une entité telle qu’un missile pourra voyager à travers plusieurs nœuds de serveur si ces nœuds de serveur ont le missile dans la zone de streaming du serveur. Un seul nœud de serveur contrôlera (aura l’autorité) sur ce missile, tandis que les autres nœuds de serveur ne verront qu’une vue client du même missile.
Les balles sont en fait créées côté client. Ainsi, une version unique de la balle est créée sur chaque nœud client et serveur, ce qui explique pourquoi j’ai utilisé une entité répliquée en réseau comme un missile dans l’exemple ci-dessus.
Lorsque vous gérez les différentes régions du monde, envisagez-vous d’héberger quatre fermes de serveurs principales, telles que les États-Unis, l’Union européenne, la Chine et l’Océanie ? Ou envisagez-vous de créer un « One-Global-Universe » ? Si c’est le cas, comment allez-vous gérer l’équilibre des joueurs avec des variations extrêmes de ping ?
Nous prévoyons toujours de conserver la distribution régionale des services sensibles au réseau. Dans le déploiement initial du streaming persistant, la base de données mondiale sera véritablement mondiale. Les shards eux-mêmes seront distribués régionalement, de sorte qu’un client de jeu se connectant à la région de l’UE sera de préférence associé à un shard de l’UE. Au fur et à mesure que la taille des shards augmente (tant pour les joueurs que pour les entités), nous prévoyons de revoir ce modèle et d’introduire également des services au niveau régional pour servir des données plus proches de la localité.
Je vis en Europe de l’Est. Après le lancement du maillage de serveurs, pourrai-je jouer avec des amis des États-Unis ?
Nous ne prévoyons pas de limiter le choix du shard et de la région pour un joueur.
Un joueur sera libre de choisir n’importe quelle région pour jouer et, dans cette région, nous autoriserons une sélection limitée de shard. Par exemple, le shard avec vos amis ou le shard sur lequel vous avez joué la dernière fois.
Comme toutes les données des joueurs sont stockées dans la base de données globale, les joueurs peuvent passer d’un shard à l’autre de la même manière qu’ils peuvent passer d’une instance à l’autre aujourd’hui. Les objets qui sont rangés seront transférés avec le joueur et seront toujours accessibles, quel que soit le shard.
Mort de la couche de réplication : Quelle sera l’expérience des joueurs si une couche de réplication est fermée/ »meurt » ? Nous savons que le graphe d’entités collectera les informations ensemencées et les réinjectera dans une nouvelle couche de réplication, mais reviendrons-nous au menu principal si la couche de réplication meurt, comme c’est le cas si un nœud de serveur meurt, ou aurons-nous une sorte d’écran de chargement qui nous mettra automatiquement dans une nouvelle couche ?
Pour répondre correctement à cette question, je dois d’abord donner un peu plus de détails sur ce à quoi ressemblera notre architecture finale. En fin de compte, la couche de réplication ne sera pas un nœud de serveur unique. Elle consistera plutôt en de multiples instances d’une suite de microservices portant des noms comme Replicant, Atlas et Scribe. L’un des avantages de ce système est que la couche de réplication elle-même pourra évoluer. Un autre avantage, plus pertinent pour cette question, est que même si un seul nœud ou une seule instance de la couche de réplication peut tomber en panne, il est très peu probable que toute la couche de réplication tombe en panne en même temps. Du point de vue du client, les nœuds de réplication sont les plus importants, car ce sont eux qui gèrent le transfert d’entités en réseau et la réplication d’état entre les clients et le jeu. Le réplicant est conçu pour ne pas exécuter de logique de jeu et, en fait, il n’exécutera que très peu de code ; pas d’animation, pas de physique, juste du code réseau. Le fait d’être construit à partir d’une base de code aussi réduite devrait permettre de réduire le nombre de bugs dans l’ensemble. Ainsi, après quelques inévitables problèmes de démarrage, nous pensons que Replicants sera assez stable. Il est également important de savoir qu’à tout moment, un même client peut être servi par plusieurs réplicants (mais ces réplicants serviront également d’autres clients en même temps). La dernière pièce du puzzle est la couche Gateway : Les clients ne se connectent pas directement aux réplicants mais à un nœud de passerelle dans la couche Gateway. Le service de passerelle est juste là pour diriger les paquets entre les clients et les différents réplicants auxquels ils parlent. Le service Gateway utilisera une base de code encore plus petite que celle des réplicants et devrait donc être encore moins susceptible de planter.
Que va vivre un client si l’un des réplicants qui le sert tombe soudainement en panne ?
Le client restera connecté au shard mais une partie ou la totalité de sa simulation sera temporairement gelée. La couche de réplication créera un nouveau nœud de réplicant pour remplacer celui qui s’est effondré et récupérera l’état de l’entité perdue dans la persistance via EntityGraph. Les passerelles clientes et les nœuds DGS qui étaient connectés à l’ancien réplicant vont rétablir la connexion avec le nouveau. Une fois que tout est reconnecté, le jeu se débloque pour les clients concernés. À ce stade, il se peut que le client subisse un certain nombre d’accrochages/téléportages d’entités. Nous espérons que l’ensemble du processus prendra moins d’une minute.
Que se passe-t-il pour un client si la passerelle qui le dessert tombe soudainement en panne ?
Le service de passerelle ne contient pas d’état de jeu et aura sa propre forme de récupération en cas de panne. Comme il s’agit d’un service beaucoup plus simple qu’un réplicant, le temps de récupération devrait être beaucoup plus rapide, de l’ordre de quelques secondes. Pendant que la récupération est en cours, le client subira un gel temporaire suivi d’un snapping/téléportage.
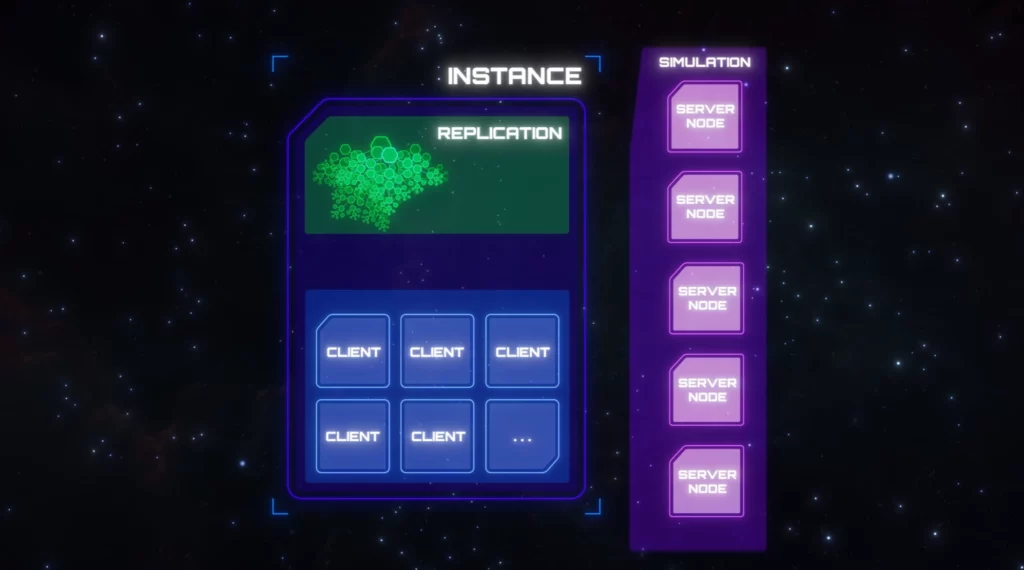
Qu’en est-il du service hybride ?
Lors de leur présentation à la CitizenCon sur le streaming persistant et le maillage de serveurs, Paul et Benoit ont parlé de la couche de réplication en termes de service hybride. Le service Hybride est, comme son nom l’indique, un hybride des services Replicant, Atlas, Scribe, et Gateway que j’ai mentionné ci-dessus (mais pas EntityGraph), ainsi qu’une poignée d’autres services non encore discutés. Nous avons choisi de développer d’abord ce service avant de le diviser en ses composants, car cela réduit le nombre de pièces mobiles que nous devons traiter en même temps. Cela nous permet également de nous concentrer sur la mise à l’épreuve de tous les grands concepts plutôt que sur le travail de routine consistant à faire communiquer correctement tous ces services individuels. Dans cette mise en œuvre initiale, la couche de réplication sera un seul nœud de serveur hybride. Si ce nœud hybride tombe en panne, la situation sera similaire à celle que connaissent actuellement les clients lorsqu’un serveur de jeu dédié tombe en panne. Tous les clients seront renvoyés au menu frontal avec la fameuse erreur 30k. Une fois que l’hybride de remplacement aura démarré, les clients pourront rejoindre le shard et continuer là où ils se sont arrêtés. Avec un peu de chance, nous pourrons implémenter le système de manière à ce que les clients reçoivent une notification à l’écran leur indiquant que le shard est à nouveau disponible et qu’une simple pression sur une touche leur permettra de rejoindre le shard (de la même manière que pour la récupération d’un crash client).
Le panel a beaucoup parlé des nœuds qui ont l’autorité d’écriture au sein d’un shard, mais qu’en est-il de l’autorité d’écriture entre des shards séparés ? Des bases de données de persistance distinctes sont-elles maintenues pour des shards séparés ou les états des éléments de l’univers seront-ils finalement synchronisés entre les shards même s’ils ont été laissés dans des états différents (par exemple, une porte est laissée ouverte sur un shard et fermée sur un autre – un shard écrira-t-il finalement son état dans la base de données, mettant à jour l’état de la porte sur l’autre shard ?)
D’une manière générale, chaque shard est sa propre copie unique de l’univers, et aucun élément du shard ne partagera son état avec un élément d’un shard différent, car chaque shard possède sa propre base de données. D’un autre côté, nous avons une base de données globale pour les données d’inventaire des joueurs. Cette base de données est utilisée pour stocker tout objet dans l’inventaire d’un joueur, et les objets peuvent être transférés entre les mondes s’ils sont d’abord rangés d’un monde à l’autre dans un inventaire et ensuite rangés dans un autre monde.
Certaines fonctionnalités, telles que les avant-postes des joueurs ou les ressources exploitables, mettent en œuvre un code spécial qui réplique un état global sur tous les shards, de sorte qu’un avant-poste peut exister sur plusieurs shards en parallèle et répliquer lentement (par rapport à la vitesse du jeu en temps réel) son état entre les shards. Il ne s’agit pas d’une réplication instantanée (une porte qui s’ouvre/se ferme ne sera pas répliquée), cependant, un état persistant comme une porte verrouillée ou déverrouillée peut être répliqué entre les shards.
Il en va de même pour les ressources minables : Ainsi, lorsque les joueurs commencent à exploiter une certaine zone, la carte globale des ressources de cette zone sera modifiée et le nombre de roches exploitables à cet endroit sera affecté sur tous les shards.
Lorsque vous avez une partie qui se déplace (voyage quantique ou autre) d’un objet à un autre, et qu’un autre nœud DGS, objet ou instance est plein, est-ce que le maillage statique / T0 créera un autre nœud DGS de manière préemptive ? Ou comment cela sera-t-il géré ?
Avec le maillage statique des serveurs, tout est fixé à l’avance, y compris le nombre de nœuds de serveur par shard et quel serveur de jeu est responsable de la simulation de quels emplacements. Cela signifie que si tout le monde dans le shard décide de se rendre au même endroit, ils finiront tous par être simulés par le même nœud de serveur.
En fait, le pire des cas est que tous les joueurs décident de se répartir entre tous les lieux assignés à un seul nœud de serveur. Dans ce cas, le pauvre serveur devra non seulement s’occuper de tous les joueurs, mais aussi de la diffusion en continu dans tous ses emplacements. La réponse évidente est d’autoriser un plus grand nombre de serveurs par shard, afin que chaque nœud de serveur ait moins d’emplacements dans lesquels il peut avoir besoin de streamer. Cependant, comme il s’agit d’un maillage statique et que tout est fixé à l’avance, le fait d’avoir plus de nœuds de serveurs par shard augmente également les coûts de fonctionnement. Mais il faut bien commencer quelque part, donc le plan pour la première version de Static Server Meshing est de commencer avec aussi peu de nœuds de serveur par shard que possible tout en testant que la technologie fonctionne réellement. Il est clair que cela posera un problème si nous permettons aux shards d’avoir beaucoup plus de joueurs que les 50 que nous avons actuellement dans nos « shards » à serveur unique.
Donc, ne vous attendez pas à ce que le nombre de joueurs augmente beaucoup avec la première version. Cela permet d’éviter qu’un nœud de serveur unique ne soit plein avant que les joueurs n’y arrivent, puisque nous limiterons le nombre maximum de joueurs par shard en fonction du pire des cas. Une fois que nous aurons mis en place ce système, nous examinerons les performances et les aspects économiques et verrons jusqu’où nous pouvons aller. Mais pour que la poursuite de l’expansion soit économiquement viable, nous devrons envisager de rendre le maillage des serveurs plus dynamique dès que possible.
Compte tenu de l’énorme volume de données circulant entre les clients et les nœuds de serveur, et de la nécessité d’une latence extrêmement faible, pouvez-vous décrire ou préciser comment vous gérez cela ou quelles technologies vous utilisez pour accélérer les choses, ou plutôt les empêcher de ralentir ?
Les principaux facteurs qui affectent actuellement la latence sont le taux de tic du serveur, le ping du client, la création d’entités et la latence des services persistants.
Le taux de tic du serveur a le plus grand effet et est lié au nombre d’emplacements qu’un serveur de jeu simule. Le maillage des serveurs devrait y contribuer en réduisant le nombre de lieux que chaque serveur de jeu doit simuler. Moins d’emplacements signifie un nombre moyen d’entités par serveur beaucoup plus faible et les économies réalisées peuvent être utilisées pour augmenter le nombre de joueurs par serveur.
Le ping du client est dominé par la distance par rapport au serveur. Nous constatons que de nombreux joueurs choisissent de jouer dans des régions situées sur des continents complètement différents. Une partie de notre code de jeu fait encore autorité sur le client, ce qui signifie que les joueurs ayant un ping élevé peuvent nuire à l’expérience de jeu de tous les autres. Il n’y a pas grand-chose que nous puissions faire à ce sujet à court terme, mais c’est un point que nous voulons améliorer une fois que le maillage des serveurs sera opérationnel.
La création lente d’entités peut entraîner une latence en retardant l’arrivée des entités sur les clients. Cela peut avoir des effets indésirables, tels que des lieux qui n’apparaissent pas complètement avant plusieurs minutes après que le quantum ait voyagé jusqu’à un lieu, la chute à travers les étages après avoir réapparu dans un lieu, des vaisseaux qui prennent beaucoup de temps à apparaître aux terminaux ASOP, la modification de la charge du joueur, etc. Les goulots d’étranglement se situent principalement au niveau du serveur. Premièrement, les entités ne sont pas répliquées sur les clients tant qu’elles n’ont pas été complètement spawnées sur le serveur. Deuxièmement, le serveur a une seule file d’attente de spawn qu’il doit traiter dans l’ordre. Troisièmement, plus un serveur a besoin d’être diffusé dans un grand nombre de lieux, plus il doit faire de spawn. Pour améliorer les choses, nous avons modifié le code de spawn du serveur pour utiliser des files d’attente de spawn parallèles. Le maillage des serveurs sera également utile, non seulement en diminuant la charge sur les files d’attente de spawn en réduisant le nombre d’emplacements dans lesquels un serveur doit se rendre, mais aussi parce que la couche de réplication réplique les entités aux clients et aux serveurs simultanément, leur permettant de spawn en parallèle.
Nous utilisons toujours certains de nos anciens services persistants, adéquats tels qu’ils ont été conçus mais connus pour avoir des problèmes de performance et d’évolutivité en fonction de nos exigences. Il peut en résulter de longues attentes lors de la récupération des données persistantes des services afin de savoir quoi faire apparaître, comme faire apparaître un vaisseau à partir d’un terminal ASOP, examiner un inventaire, changer la charge du joueur, etc. Étant donné que le streaming persistant et le maillage de serveurs augmenteront considérablement la quantité de données que nous devons faire persister, nous savions que nous devions faire quelque chose à ce sujet. C’est pourquoi Benoît et son équipe chez Turbulent ont complètement réinventé la façon dont nous allons faire persister les données sous la forme d’EntityGraph, qui est un service hautement évolutif construit au-dessus d’une base de données hautement évolutive qui est optimisée pour exactement le type d’opérations de données que nous effectuons. En plus de cela, nous développons également la couche de réplication, qui agit comme un cache en mémoire hautement évolutif de l’état actuel de toutes les entités d’un shard, éliminant ainsi la nécessité de la majorité des requêtes que nous envoyions aux services persistants existants. C’est vrai, il y aura des services hautement évolutifs jusqu’au bout !
Pour aider à réduire/éliminer toute latence supplémentaire que la couche de réplication pourrait introduire, nous la construisons pour qu’elle soit gérée par événement plutôt que par tic-tac comme un serveur de jeu traditionnel. Cela signifie que lorsque des paquets arrivent, il les traite immédiatement et envoie la réponse et/ou transmet les informations aux clients et serveurs de jeu concernés. Une fois que le travail sur la version initiale de la couche de réplication sera terminé (le service hybride), nous effectuerons un passage d’optimisation pour nous assurer qu’elle est aussi réactive que possible. Et, bien qu’il s’agisse en fin de compte d’une décision à prendre par DevOps, nous les déploierons dans les mêmes centres de données que les serveurs de jeu eux-mêmes, de sorte que la latence du réseau sur le fil due au saut supplémentaire entre la couche de réplication et le serveur de jeu devrait être inférieure à une milliseconde. Oh, et ai-je mentionné que la couche de réplication sera hautement évolutive ? Cela signifie que si nous détectons que la couche de réplication provoque des points de latence dans certaines parties du jeu, nous pourrons la reconfigurer pour remédier au problème.
Source : server meshing and persistent streaming q&a [Anglais]